Over the past couple of years, enterprises have rapidly embraced Generative AI. Teams are building copilots, document assistants, intelligent search systems, and autonomous workflows faster than ever before. In many cases, a proof of concept (PoC) can be built within days using foundation model APIs and modern orchestration frameworks.
But moving from a successful demo to a reliable production system is where most organizations begin to struggle.
A chatbot that performs well in a controlled environment may suddenly generate inaccurate responses in production. Retrieval pipelines start surfacing irrelevant information. Token consumption rises unexpectedly. Latency increases during peak usage. Security and compliance teams raise concerns around sensitive data exposure. What initially looked like a straightforward AI deployment quickly becomes an operational challenge.
This is exactly where LLMOps Strategy comes into play.
What is LLMOps?
LLMOps is the operational framework that supports the lifecycle of Large Language Model (LLM) applications in production environments. It includes everything that happens beyond the user simply interacting with a GenAI application.
From data analysis and preprocessing to observability, governance, monitoring, experimentation, evaluation, and optimization, LLMOps strategy ensures that AI systems remain scalable, reliable, secure, and cost-efficient over time. Small changes in prompts, retrieval context, or model versions can significantly impact output quality. As organizations scale AI across business functions, operational maturity becomes just as important as model capability.
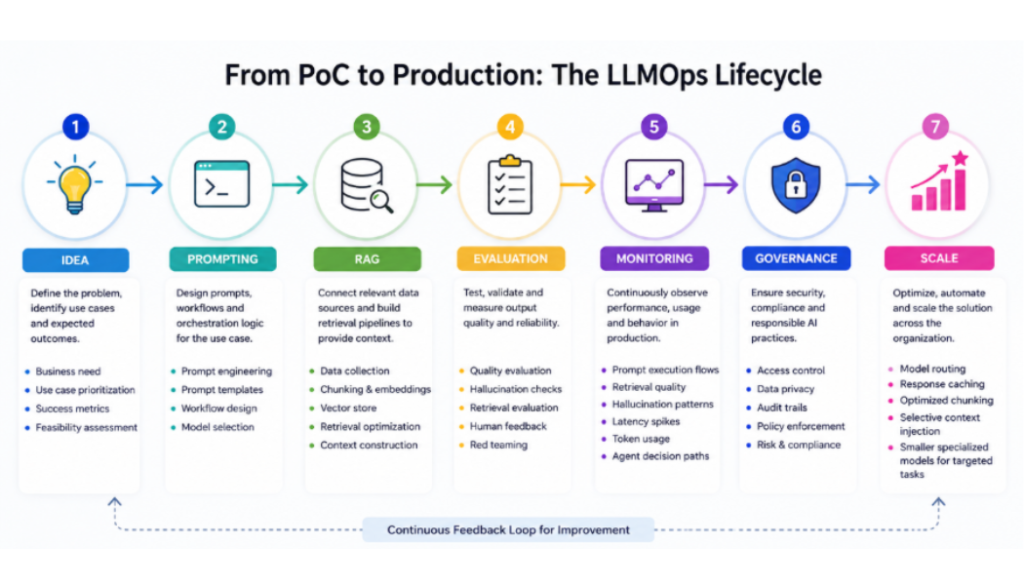
How to Build an LLMOps Pipeline
Building a successful GenAI application requires far more than simply connecting an LLMOps Strategy to a user interface. Behind every reliable AI system is an operational pipeline that continuously manages data, prompts, monitoring, governance, and optimization at scale.
The LLMOps Strategy lifecycle typically begins with data preparation and knowledge engineering, where enterprise data is cleaned, structured, chunked, and optimized for retrieval systems such as RAG pipelines. This stage often includes embedding generation, optimized chunking strategies, and selective context injection to ensure the model receives the most relevant information during inference.
Once the data foundation is established, teams move into prompting and orchestration, designing prompts, workflows, and agent interactions that power the overall user experience. As GenAI systems become more complex, orchestration layers also help manage agent decision paths, tool usage, and interactions between multiple models and APIs.
As applications evolve, organizations enter the experimentation and evaluation phase, where prompts are tested, outputs are validated, hallucination patterns are analyzed, and retrieval quality is continuously improved through iterative feedback loops. This stage is critical for improving reliability and maintaining response consistency across different use cases.
After validation, the system progresses into deployment and scaling, where infrastructure, latency, and performance optimization become essential for handling production workloads. Modern LLMOps strategy often include model routing, response caching, and the use of smaller specialized models for targeted tasks to improve efficiency and reduce operational costs.
However, deployment is only the beginning. Enterprise GenAI systems require continuous observability and monitoring to track prompt execution flows, retrieval quality, hallucination patterns, latency spikes, token usage, and overall system reliability in real time. Observability provides the visibility needed to identify operational bottlenecks and optimize system performance over time.
Alongside this, governance and security ensure responsible AI adoption through access controls, compliance safeguards, auditability, and data protection mechanisms.
Finally, mature LLMOps Strategy pipelines rely on continuous optimization, which involves refining prompts, improving retrieval strategies, reducing operational costs, and adapting AI systems to evolving business requirements over time.
Together, these stages form the operational backbone that transforms AI experiments into scalable, enterprise-ready GenAI solutions.
What a Mature LLMOps Architecture Looks Like
Traditional MLOps frameworks are not sufficient for managing Large Language Models (LLMs) because GenAI systems introduce challenges far beyond conventional machine learning workflows. Unlike traditional ML models, LLMOps Strategy require handling massive unstructured datasets, prompt engineering, retrieval pipelines, observability, governance, hallucination monitoring, and continuous cost optimization.
A mature LLMOps Strategy architecture typically includes multiple interconnected layers working together to ensure reliability and governance.
This often includes:
- foundation model providers
- prompt management systems
- security and governance controls
- human feedback mechanisms
The objective is not just to generate responses, but to create enterprise-grade AI systems that are traceable, auditable, scalable, and aligned with business objectives.
Organizations that invest in operational maturity early are significantly better positioned to scale GenAI initiatives across departments and workflows.
The Future of LLMOps
As AI systems become increasingly autonomous, LLMOps will continue evolving beyond monitoring and deployment.
The next generation of LLMOps Strategy will likely focus on:
- autonomous agent orchestration
- self-healing AI pipelines
- synthetic evaluation frameworks
Enterprises are moving toward environments where AI systems not only assist workflows but actively coordinate and execute them. In such environments, operational reliability becomes mission-critical.
Ready to move beyond AI experimentation and build production-ready GenAI solutions?
At Nallas, we help enterprises design, operationalize, and scale secure, reliable, and cost-efficient AI systems tailored to real business outcomes.
Connect with our experts to accelerate your GenAI journey with the right strategy, architecture, and LLMOps Strategy foundation. https://outlook.office.com/book/NallasGENAI@nallas.com/?ismsaljsauthenabled




")
")




")
")


